
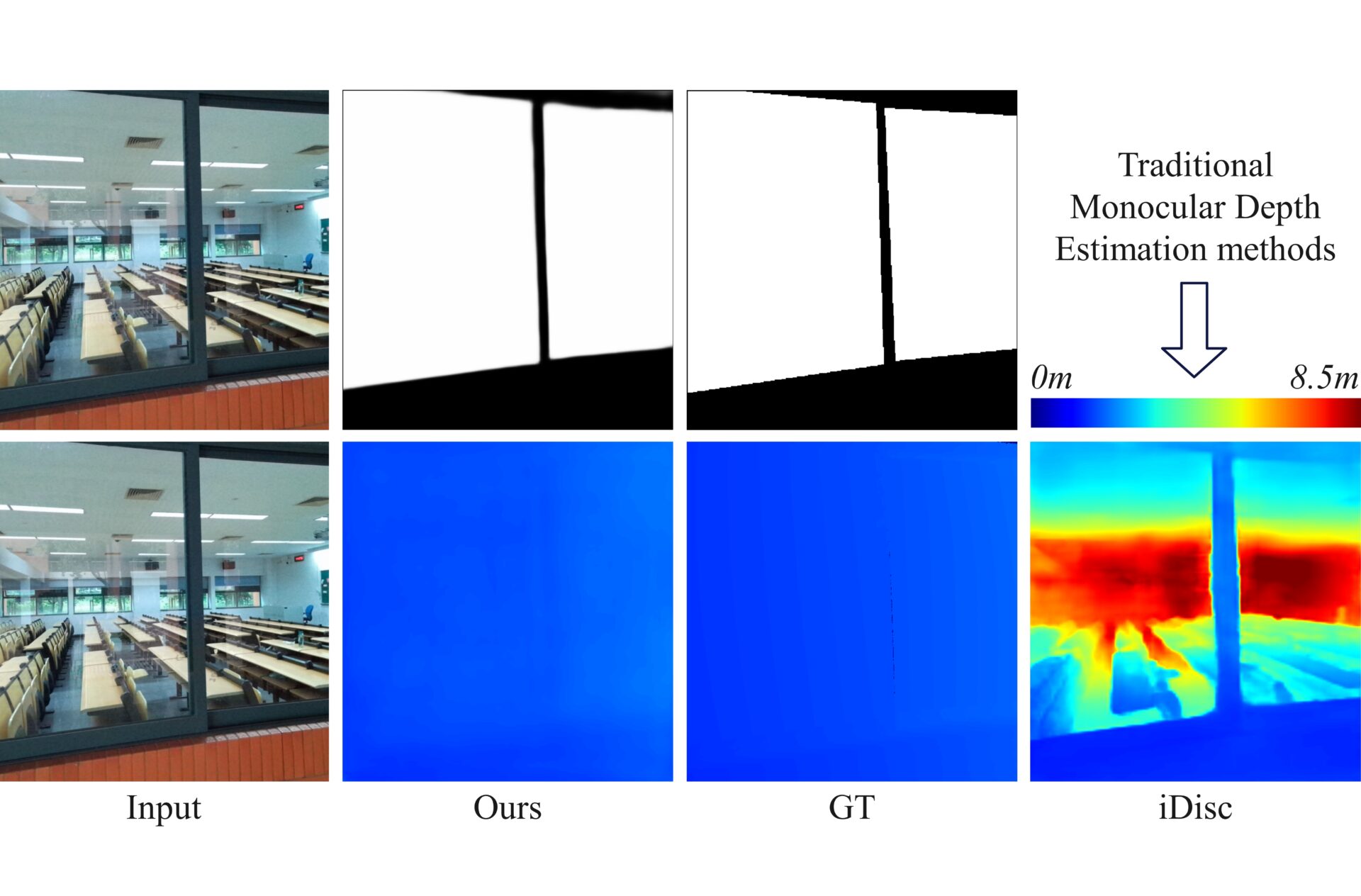



Monocular depth estimation performs regression prediction for each pixel in the input RGB image, ultimately generating a 16-bit depth image. In the output depth map, the pixel values range from 0 to 65536, representing the distance of the pixel from the camera, measured in millimeters. However, existing monocular depth estimation methods are unable to perform depth estimation for glass surfaces, meaning they do not treat glass surfaces as obstacles and therefore fail to predict the distance of the glass surface from the camera. They tend to ignore the glass surface and directly estimate the depth of objects behind the glass surface or even reflections on the glass.
単眼深度推定は、入力RGB画像の各ピクセルに対して回帰予測を行い、最終的に16ビットの深度画像を生成する。出力される深度マップでは、ピクセル値は0から65536の範囲にあり、カメラからピクセルまでの距離をミリメートル単位で表している。しかし、既存の単眼深度推定手法はガラス表面の深度推定を行うことができず、ガラス表面を障害物として扱わないため、ガラス表面からカメラまでの距離を正確に予測することができない。これらの手法は、ガラス表面を無視してガラス表面の奥にある物体やガラス表面に映り込む反射物の深度を直接推定する。

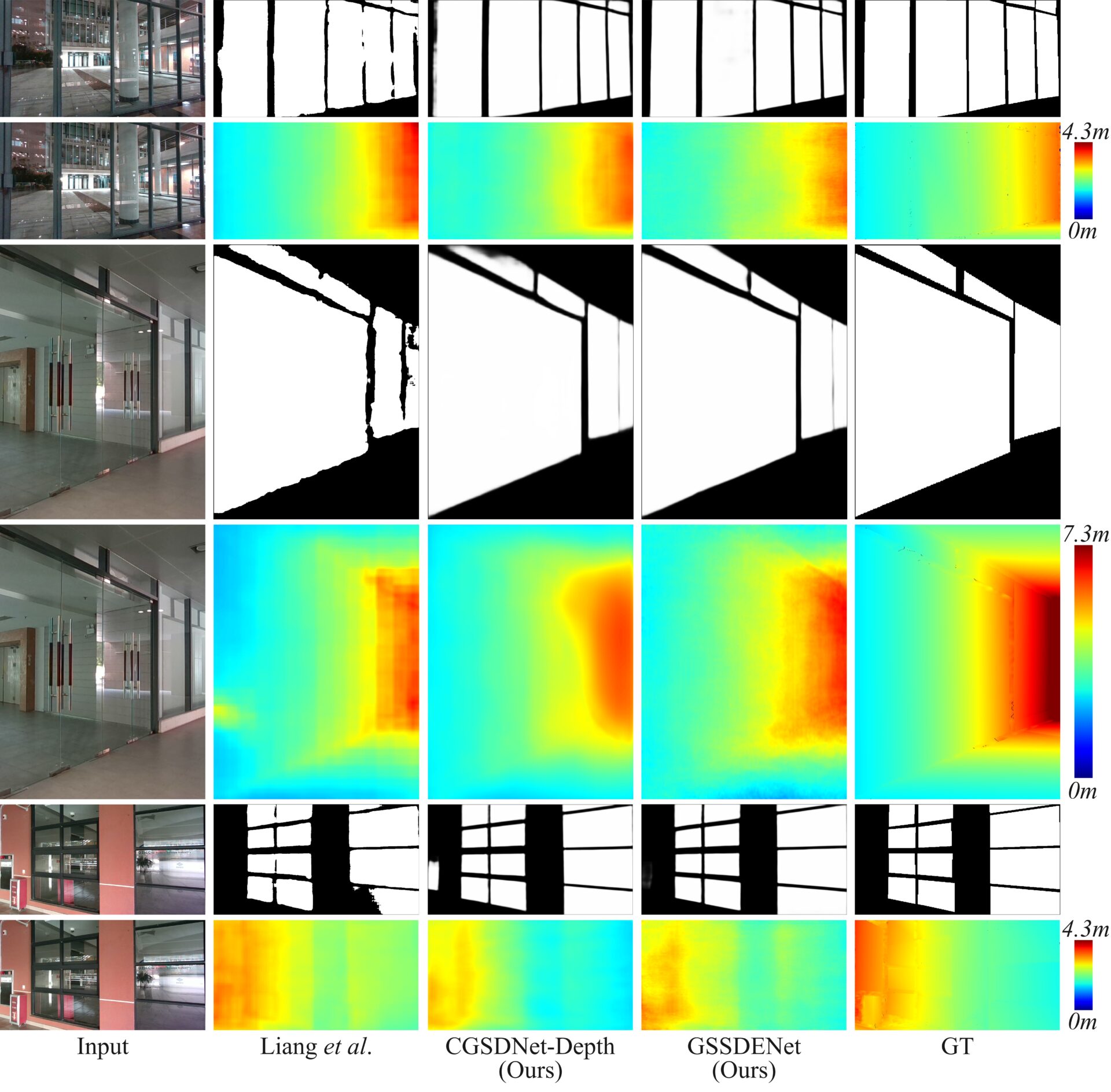
Glass Surface Depth Estimation is a special category of monocular depth estimation. Furthermore, glass surface segmentation and depth estimation networks can simultaneously output mask images and depth maps of glass surfaces from RGB inputs, providing the 3D positional information of glass surfaces to Visual SLAM, thereby improving its performance in glass surface scenarios. Existing Liang \textit{et al.}’s method correctly outputs the depth values of glass surfaces when treated as obstacles, but its performance in segmenting glass surfaces is still significantly lacking, particularly at the boundaries of the glass surfaces, as shown in the red box in the following Figure.
ガラス表面深度推定は、単眼深度推定の特別な種類である。さらに、ガラス表面セグメンテーションと深度推定ネットワークは、RGB入力からガラス表面のマスク画像と深度マップを同時に出力することができ、ガラス表面の3次元位置情報をVisual SLAMに提供し、ガラス表面シナリオでの性能を向上させる。既存のLiangらの手法では、ガラス表面を障害物として扱った場合、深度値を正しく出力できるが、ガラス表面のセグメンテーション性能にはまだ問題があり、特にガラス表面の境界部分でその性能が著しく不足していることが、以下の図の赤枠で示されている。

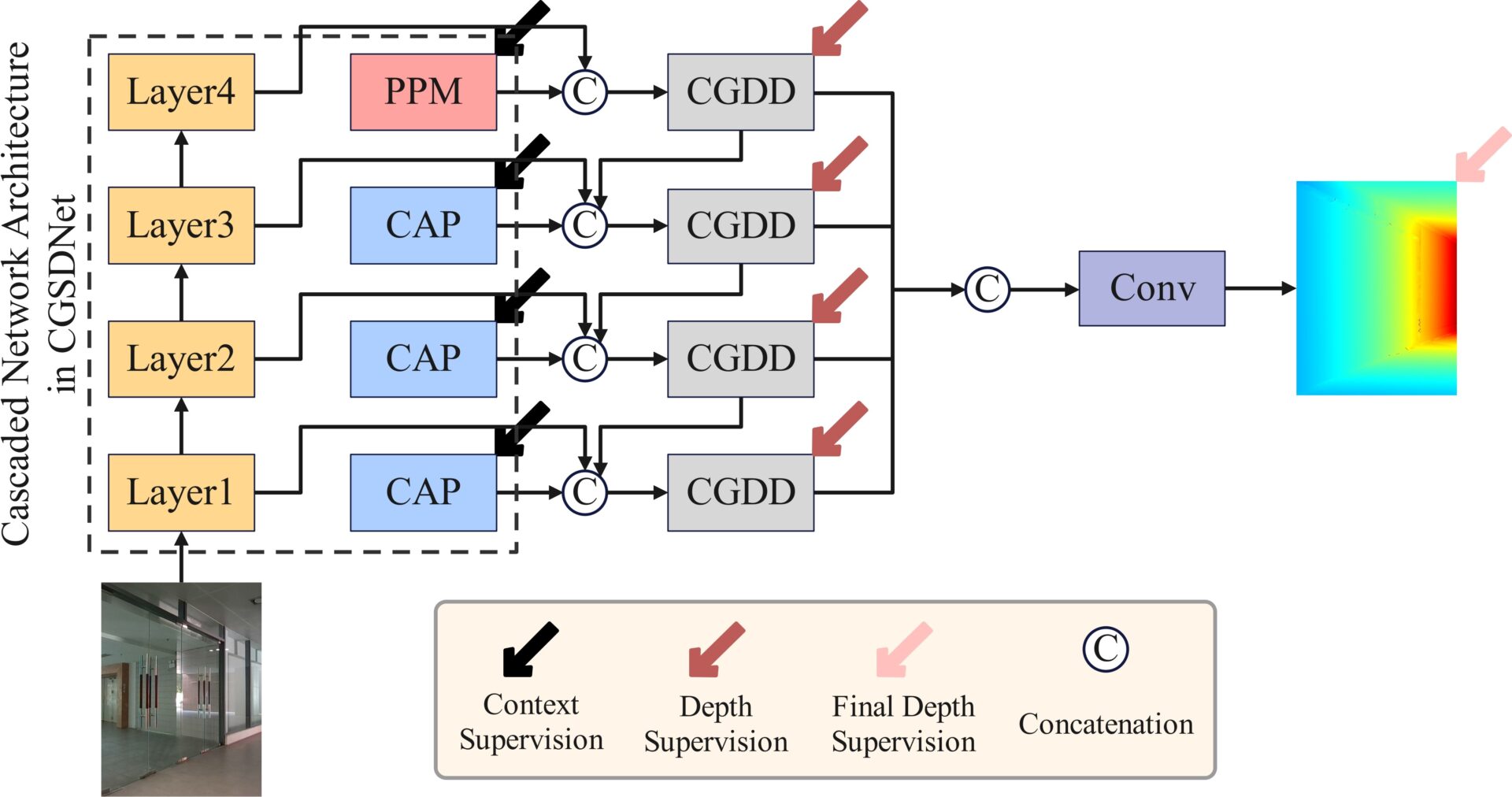
To address the issues in existing research on glass surface segmentation and depth estimation, we propose two networks capable of simultaneously achieving high-quality glass surface segmentation and depth estimation: CGSDNet-Depth and GSSDENet. Our methods introduce the Context Guided Depth Decode (CGDD) and Context Guided Depth Attention (CGDA) modules, both of which leverage refined glass surface contextual features to guide the generation of glass surface depth features.
既存のガラス表面セグメンテーションと深度推定に関する研究の課題に対処するため、私たちは高品質なガラス表面セグメンテーションと深度推定の結果を同時に出力できる2つのネットワーク、CGSDNet-DepthとGSSDENetを提案した。我々の手法では、Context Guided Depth Decode(CGDD)とContext Guided Depth Attention(CGDA)モジュールを提案し、高品質なガラス表面のコンテキスト特徴を活用して、ガラス表面の深度特徴の生成を指導する。
Publication
- Zeyuan Chen, Ziquan Wang, Qiang Gao, Masahiko Mikawa and Makoto Fujisawa, “Dense Reconstruction and Localization in Scenes with Glass Surfaces Based on ORB-SLAM2”, ICPR, 2024. DOI: 10.1007/978-3-031-78113-1_26.
- Zeyuan Chen, Qiang Gao, Masahiko Mikawa and Makoto Fujisawa, “GSSDENet: Network for Simultaneous Glass Surface Segmentation and Depth Estimation”, submitted.